.png)
70%
基础设施维护减少
20+
内置AI服务
数十亿
关联数据规模支持
已在全球 200+ 生产环境中验证:







更简单的方法
五个系统、二十三个集成步骤,一个平台取代全部。
大多数企业在构建企业级 AI 时,最终都会形成一套拼凑式技术栈:向量数据库、图数据库、搜索引擎彼此拼接,再通过自定义检索管道与后期补充的数据治理层勉强维系。

93% 的企业管理者认为:
AI 洞察必须结合业务上下文,才能真正产生价值。
· 拼凑式技术栈
- 独立向量数据库
Pinecone、Weaviate 或 Qdrant 被额外接入原本并非为向量检索设计的数据库体系。 - 外挂式图数据库
Neo4j 或 TigerGraph 独立运行,缺乏统一查询语言与数据模型。 - 独立搜索引擎
Elasticsearch 或 OpenSearch 需要单独维护集群。 - 自定义 RAG 流程
通过 LangChain 或 LlamaIndex 手工拼接,扩展与稳定性不足。 - 后置治理体系
权限控制、数据隐私与安全治理往往在最后阶段才被补充。
· Arango AI上下文数据平台
- 内置向量能力
无需额外部署向量数据库。 - 内置图数据库能力
原生支持关系遍历,无需独立图数据库 - 内置 ArangoSearch
原生集成全文检索,无需额外搜索集群。 - 内置 AutoRAG
自动选择 GraphRAG、HybridRAG 或 VectorRAG。 - 内置治理能力
从第一天开始即具备 RBAC、数据血缘与可观测性。
| 对比维度 | 多数据库集成方案 | ArangoDB 原生融合 |
|---|---|---|
| 存储引擎 | 多个独立引擎(RocksDB、Lucene、专用图存储等) | 单一 C++ 核心,共享存储层 |
| 数据一致性 | 最终一致性,依赖同步管道延迟 | 跨模型 ACID 事务,实时一致 |
| 查询延迟(跨模型) | 50-200 毫秒(多次网络往返) | 5-20 毫秒(内存内计算) |
| 运维复杂度 | 多套系统,独立运维,协调困难 | 单一部署、监控、备份流程 |
| 团队技能要求 | 需掌握多种查询语言和运维工具 | 统一 AQL 技术栈 |
| 扩展性 | 各系统扩展策略不一致,需单独规划 | 统一集群,自动分片,线性扩展 |
4.0 版本新特性
Arango AI上下文数据平台 - 五项全新能力
Arango AI上下文数据平台 4.0 新增了自然语言交互、自动构建图、智能检索以及可视化探索功能——提供 AI 所需的推理上下文、企业要求的可信度,以及支持生产环境运行的全部扩展能力。

Ada
AI 数字助手,支持自然语言开发

AQLizer
自然语言转优化后的 AQL 查询

Graph Visualizer
可视化查看和探索上下文关系

AutoGraph
自动构建上下文知识图谱

AutoRAG
在图、向量、文档数据间智能检索
工作原理
从原始数据到生产级智能体 - 全自动
数据从任意源流入 → AutoGraph 构建知识图谱 → AutoRAG 选择正确的检索策略 → 您的智能体获得互联、受控、可追溯的业务上下文。
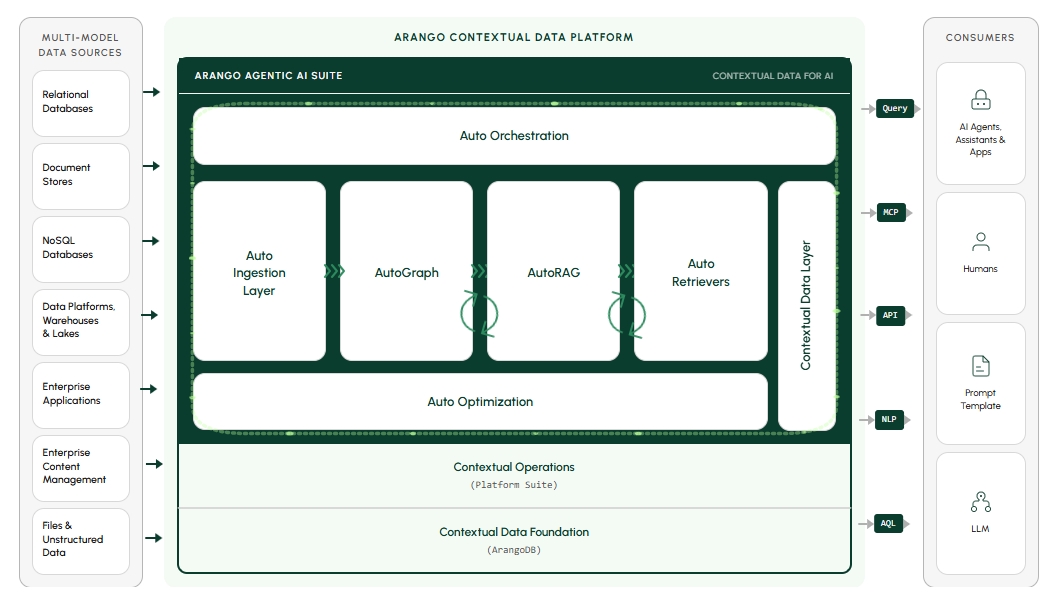
4.0 新增:
Arango Agentic AI 套件
查看内部详情:
自动化层
每个组件处理管道的不同阶段:数据进入、上下文构建、检索策略自动选择、您的智能体与全部数据连接。
AutoGraph - 知识建模
AutoGraph 是 Arango 的自动化知识图谱构建器。它接收您的企业数据,无需手动设计本体即可发现实体间关系。投入数百万份文档,AutoGraph 就能构建出智能体所需的、可直接用于检索的结构。
AutoRAG - 检索策略
AutoRAG 是 Arango 的适应性检索层,它在运行时为每个查询自动选择正确的检索策略——GraphRAG、HybridRAG 或 VectorRAG。支持多跳查询的深度搜索,无需手动配置管道。
ContextRAG - 知识组织
将企业知识组织成语料图谱,并在正确时机提供正确的上下文。统一处理结构化和非结构化数据,通过混合检索将碎片化数据转化为可信上下文。
每一次查询都内置智能能力
您的智能体不仅检索数据,还会对结果排序、自适应调整,并证明数据来源。

多模态检索
在一个管道中同时检索文档、嵌入向量、结构化记录和图关系数据。

关系遍历
支持跨实体、事件与系统的多跳关系推理,突破纯向量搜索的局限。

证据排序
基于相关性、关系路径与数据来源,对结果进行可信排序,提供可解释的 AI 响应。

查询自适应
随着新信号的出现,持续优化检索路径和推理步骤,不断提高准确性。
企业级治理能力
从第一条查询开始即具备治理能力,而不是后期补充。

数据溯源
每个答案都可追溯至其来源。

合规性
完整审计日志,记录所有查询行为。

时间旅行
支持查询任意历史时间点的数据状态。

安全性
支持行级权限控制(Row-Level Access Control)。
Vector 发现相似内容,Graph 发现真实关联
传统 RAG 基于语义相似性检索文档,GraphRAG 则通过实体关系遍历,实现多跳推理与业务上下文关联,这是单纯向量搜索无法实现的。AutoRAG 会在查询阶段自动选择 GraphRAG 、HybridRAG或VectorRAG。
GraphRAG 带来的价值:
– 遍历向量搜索无法看到的实体关系
– 跨文档、图谱、运维信号进行多跳推理
– 每个答案可追溯——可解释、可审计、受治理
– 图 + 向量在同一个查询中

上下文改变结果
以下每个用例都面临同样的问题根源:数据分散在不同系统,缺乏对关系的理解,决策无法解释。
Arango 一次性解决这三个问题。
Arango 一次性解决这三个问题。

客户支持
智能体需要跨系统连接客户记录、产品历史、已知问题和解决方案策略。
使用 Arango:关系感知检索可在单次查询中追踪客户问题——涵盖工单历史、产品日志、已知缺陷和政策规则。

欺诈检测
智能体需要实时追踪账户、设备、身份和事件之间的关系,且具备完整可审计性。
使用 Arango:图遍历能发现纯向量检索无法捕捉的欺诈环和异常模式。RBAC 确保每次查询都遵守访问策略。

知识助手
智能体需要了解您组织的知识——概念如何在团队、系统、时间维度上相互关联。
使用 Arango:AQLizer 将自然语言转化为跨结构化和非结构化数据的查询。基于完整图景给出答案。

AIOps 与根因分析
智能体需要关联告警、追踪基础设施依赖链上的事件,并实时推荐解决方案。
使用 Arango:日志、拓扑、告警、变更历史在同一平台统一查询。图遍历可将服务降级问题追踪到每一个依赖环节,直至根因。

工程研发 AI
智能体需要访问代码、架构决策、运行手册和工程上下文,并具备足够的关系感知能力以给出可落地的答案。
使用 Arango:深度搜索可跨代码库、文档和故障历史追踪依赖关系,揭示语义搜索会遗漏的上下文。

基础设施图谱
智能体需要实时、互联的基础设施视图——资产、依赖、告警、变更历史。
使用 Arango:统一的基础设施拓扑图,让智能体可将服务降级问题回溯到三跳之外的一次配置变更。
4.0 新增
使用您自己的 LLM和框架,Arango 全面兼容。
LLM+Agent Framework 集成
OpenAI、Anthropic、Mistral、LiteLLM、LangChain、LlamaIndex、NVIDIA Triton、Any LLM
驱动支持
Python、JavaScript、Java、Go、.NET、Spring
多种部署方式
Self-service cloud、VPC、On-premises、Air-gapped
常见问题解答
什么是 Arango AutoGraph?
Arango AutoGraph™ 是 Arango 的自动化知识图谱构建器。它接收企业数据(结构化、半结构化和非结构化),无需手动设计本体即可发现实体间关系。输出一个受治理的、可直接用于检索的知识图谱,AI 智能体、助手和应用可以立即查询。
什么是 AutoRAG?
Arango AutoRAG™ 是 Arango 的适应性检索层。它在运行时评估每个查询,并自动选择最优检索策略——GraphRAG(用于关系遍历)、HybridRAG(语义+结构化检索)、VectorRAG(嵌入向量相似度)或 Deep Search(多跳查询)。
GraphRAG 和 VectorRAG 有什么区别?
VectorRAG 基于嵌入向量相似度检索文档。GraphRAG 在知识图谱中遍历实体关系——这是向量搜索无法触及的多跳连接。Arango 的 AutoRAG 会根据查询类型自动在两者(以及 HybridRAG)之间进行选择。
上下文数据平台会替代 LangChain 或 LlamaIndex 吗?
不会。Arango 与 LangChain、LlamaIndex 及其他框架集成。它提供受治理的数据基础和检索层(AutoGraph、AutoRAG 和 Agent Runtime),位于您的 LLM 和编排框架之下。Arango 替代的是“拼凑式数据库架构”,而非 AI 开发框架。
什么是 AQLizer?
Arango AQLizer 将自然语言查询转换为 AQL(ArangoDB 查询语言)。它让 AI 智能体、助手和应用能够查询图、向量和文档数据,而无需用户或开发者直接编写 AQL。它有助于简化开发、优化查询性能,使连接企业数据的访问和推理更加便捷。
如何为 AI 智能体实施数据治理?
Arango 内置了 RBAC(基于角色的访问控制)、审计轨迹、数据溯源和查询日志。AI 智能体、助手或应用产生的每个答案都可以追溯到其源数据。治理内置于数据层,而非事后附加。它满足欧盟 AI 法案对可解释性和决策可追溯性的要求。
哪些 LLM 可与 Arango 上下文数据平台配合使用?
Arango 适用于任何 LLM。它提供了针对 OpenAI、Anthropic、Mistral、LiteLLM、NVIDIA Triton、LangChain 和 LlamaIndex 的集成。由于它作为数据和检索层,LLM 的选择权完全在开发者手中。

