.png)

AI技术的演进浪潮
现代AI的企业成功,特别是在推理、决策和智能体应用方面,需要先构建密集、高性能的纵向扩展基础设施,然后再进行横向扩展。

早期阶段
2021年之前
- 现成应用中的AI功能
- 静态服务器与固定GPU配置
大预言模型(LLM)训练时代
2021年—2025年
- 超大规模厂商”跑马圈地”专注LLM训练导致GPU短缺
- 大语言模型走向主流
本地推理时代
2025年及之后
- 推理:AI向边缘迁移
- 思考:推理、RAG与调优
- 行动:智能体和MCP
LIQID:弥合企业GPU基础设施缺口
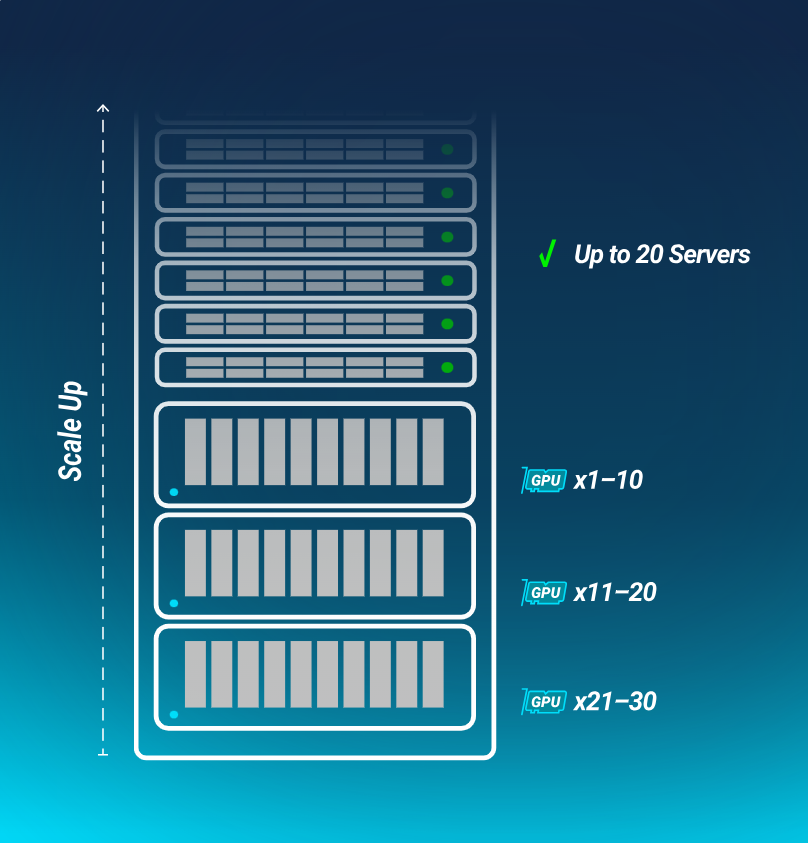
N-Way服务器
×8
1–8 块 GPU(每块 600W)
✅简化管理
✅定向部署
🚫固定僵化架构
🚫高功耗
×30
支持最高 30 块 GPU(每块 600W)

✅纵向+横向扩展
✅企业级的推理
✅可组合架构
✅功耗与成本双优化
AI Factory
×72
最高可配置 72 块 GPU(每机架 125kW)
✅卓越的大规模语言模型训练
✅海量统一计算资源
🚫仅适配高端算力场景
🚫功耗/成本高
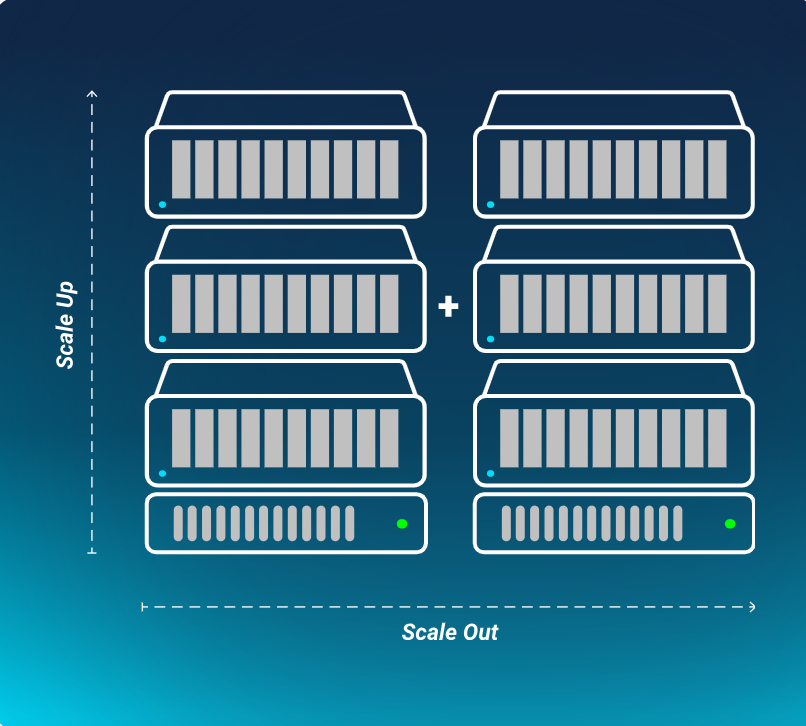
纵向扩展与横向扩展
- 纵向扩展(Scale Up):单台服务器可扩展至30块GPU(支持NVIDIA H200、RTX Pro 6000等),动态分配内存,支持超大规模AI模型。
- 横向扩展(Scale Out):开放架构支持任意网络结构,多系统集群化实现高性能,无需迁移至昂贵专用AI工厂。
LIQID纵向扩展方案
- 弹性配置:从1到30块GPU即时调配,支持600W高性能设备(如Intel Gaudi 3、d-Matrix),无集群互连损耗。
- 性能优化:GPU直连NVMe存储,提升AI/HPC负载30%性能,降低延迟。单CPU主机支持大规模GPU+内存,减少硬件、功耗与散热需求。
- 快速部署:通过Liqid Matrix软件秒级分配GPU、内存及存储,精准匹配工作负载。

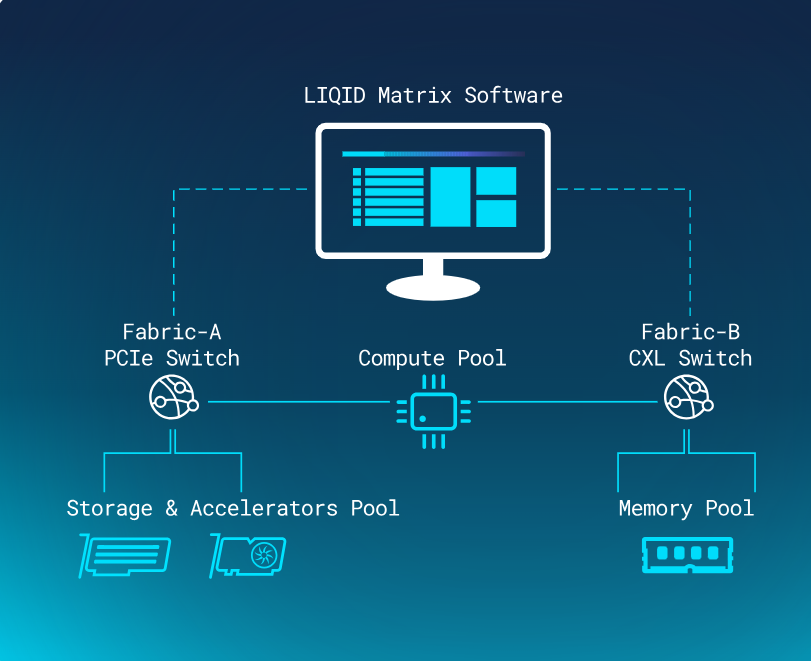
LIQID横向扩展方案
- 基于开放标准,支持现有网络硬件及协议(如RoCE v2/v3、InfiniBand)。
- 无缝对接Kubernetes、VMware、Slurm等编排与调度工具。支持多租户,跨部门共享资源(如推理模型/LLM微调),提供高可用性(HA)与分布式管理。
- 适配新兴技术如Nvidia Fusion、Ultra Ethernet。
业界首个也是唯一的可组合纵向扩展单一界面
- 业界唯一实现GPU与内存可组合性的管理界面,支持纵向/横向扩展。
- 软件定义故障设备断电与虚拟替换,减少停机时间。
- 可以通过图形界面或REST API操作,集成Kubernetes、Ansible等生态工具。
LIQID使命宣言:重塑本地与边缘AI基础设施能效标准

联系我们
与我们的产品专家交流,了解LIQID如何为您的数据中心带来更大的敏捷性和价值。
产品服务
产品咨询&选型指导
产品文档&资料
方案设计&报价
技术支持
技术培训
定制方案开发
售后支持服务
资源中心
行业动态&趋势
技术干货&案例
产品更新&发布
联系我们
24小时快速响应
资深工程师对接
量身定制解决方案

