.png)
摘要
企业AI知识检索正从Vector RAG演进至GraphRAG及混合架构。Vector RAG基于向量相似度,擅长文档问答但难以处理实体关系;GraphRAG利用知识图谱与图遍历,擅长多跳关系推理;Hybrid RAG融合二者,支持语义+关系联合检索。企业复杂数据场景推荐混合架构。
随着大语言模型(LLM)的广泛应用,越来越多企业开始构建自己的 AI 知识问答系统。然而,仅依赖模型本身往往无法获得准确、最新的企业知识,因此 Retrieval-Augmented Generation(检索增强生成,简称 RAG)成为当前主流解决方案。
RAG 的核心思想是:在模型生成回答之前,先从企业数据中检索相关信息,再将这些信息作为上下文提供给大语言模型,从而提升回答的准确性并减少“幻觉”。
目前企业构建 RAG 系统主要有三种技术路线:
1. Vector RAG(基于向量数据库)
2. GraphRAG(基于知识图谱)
3. Hybrid RAG(向量 + 知识图谱混合架构)
本文将从系统架构角度解析这三种方案,并说明它们在企业场景中的真实应用方式。
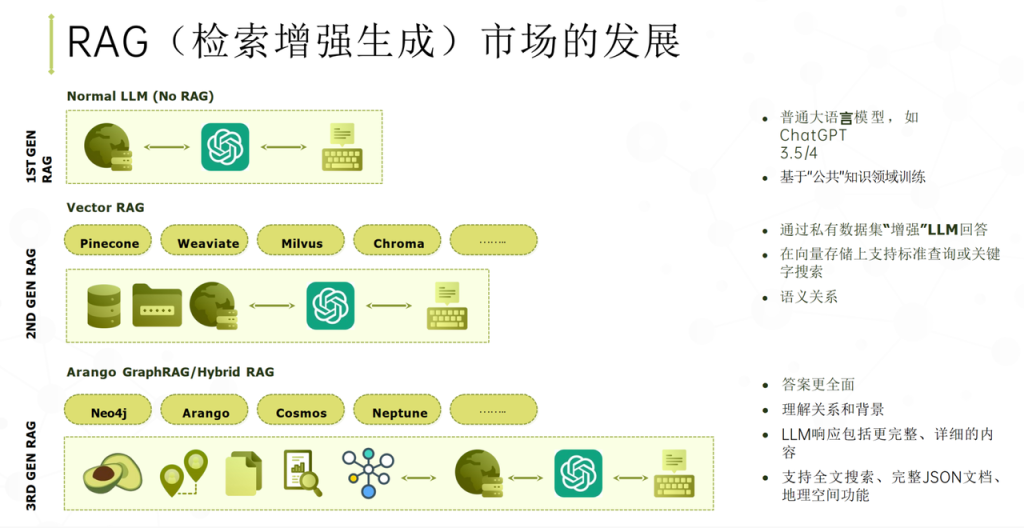
一、Vector RAG:目前最常见的AI检索架构
当前绝大多数企业 AI 问答系统采用的是 Vector RAG 架构。这种方法通过将文本转换为向量(embedding),再利用向量相似度进行检索。
典型架构如下:
企业数据源
(文档 / PDF / Wiki / 数据库)
│
▼
文档切分 (Chunking)
│
▼
Embedding模型
(文本 → 向量)
│
▼
向量数据库
(Vector Database)
│
▼
相似度搜索
Top-K
│
▼
LLM
│
▼
回答
1. 数据预处理:文档切分
企业知识通常来自:
- 产品文档
- Wiki知识库
- PDF文件
- 数据库记录
- API数据
由于大语言模型存在上下文长度限制,需要将文档切分为较小的文本片段(chunk)。
常见 chunk 大小为:
200 ~ 800 tokens常见切分策略包括:
- Fixed-size chunk
- Sliding window
- Semantic chunk
合理的切分方式会直接影响检索效果。
2. Embedding:文本向量化
在 Vector RAG 中,文本会通过 embedding 模型转换为向量表示。
常见 embedding 模型包括:
- OpenAI text-embedding
- BGE
- E5
- Sentence Transformers
例如:
文本:
"How to reset password"
Embedding:
[0.34, -0.12, 0.77, ...]向量本质上是 语义空间中的坐标,语义相似的文本向量距离会更接近。
3. 向量数据库检索
这些 embedding 会存储在向量数据库中,例如:
- FAISS
- Milvus
- Pinecone
- Weaviate
这些数据库通常使用 近似最近邻算法(ANN) 进行搜索,例如:
- HNSW
- IVF
- PQ
查询时系统会返回 Top-K 最相似的文本片段。
4. LLM生成回答
最终构建 Prompt:
用户问题
+ 检索到的文档片段然后发送给大语言模型,例如:
- GPT‑4
- Claude
- Llama
模型会根据上下文生成回答。
二、Vector RAG 的局限性
Vector RAG 在 文档问答 场景中表现很好,但在复杂数据场景中存在明显限制。
核心原因是:向量只能表达语义相似度,无法表达实体关系。
例如问题:
Which suppliers provide parts used in Tesla batteries?这个问题涉及多个关系型实体:
• Tesla
• battery
• supplier
• component
向量搜索很难准确推理这种关系链。因此出现了新的架构方向:GraphRAG
三、GraphRAG:基于知识图谱的 RAG 架构
GraphRAG 的核心思想是:让 LLM 使用结构化知识图谱进行检索,而不是只依赖文本相似度。
GraphRAG 架构如下:
企业数据
(文档 / CRM / ERP / API)
│
▼
信息抽取
(NER + Relation Extraction)
│
▼
知识图谱构建
Nodes + Relationships
│
▼
图数据库
│
▼
图遍历查询
Graph Traversal
│
▼
上下文构建
│
▼
LLM
│
▼
回答1. 实体识别(NER)
系统首先从文本中提取实体,例如:
"Microsoft acquired GitHub in 2018"提取:
- Microsoft(公司)
- GitHub(公司)
- 2018(时间)
2. 关系抽取
接下来识别实体之间的关系:
Microsoft --acquired--> GitHub最终形成知识图谱结构:
Microsoft
│
└── acquired → GitHub
│
└── founded_by → Tom Preston-Werner3. 图数据库存储
知识图谱通常存储在图数据库中,例如:
- Neo4j
- TigerGraph
- ArangoDB
其中 ArangoDB 是一种多模型数据库,同时支持:
- 文档数据库
- 图数据库
- Key-Value
- 向量搜索
这使其适合构建 GraphRAG 或 Hybrid RAG 架构。
4. 图遍历查询
GraphRAG 的核心能力是:Graph Traversal(图遍历)
例如查询:
MATCH (c:Company)-[:acquired]->(target)
WHERE c.name="Microsoft"
RETURN target系统可以通过多跳关系查询获得完整上下文。
四、企业真实架构:Hybrid RAG
在实际企业系统中,最先进的方案通常不是纯 Vector RAG,也不是纯 GraphRAG,而是 Hybrid RAG。
典型架构如下:
用户问题
│
▼
查询理解层
│
┌───────────┴───────────┐
│ │
▼ ▼
向量语义搜索 图关系搜索
(Vector Retrieval) (Graph Query)
│ │
▼ ▼
文档片段 结构化关系
│ │
└───────────┬───────────┘
▼
Context Builder
│
▼
LLM
│
▼
回答这种架构结合了三种能力:
- 语义检索:基于向量相似度获取相关文档片段;
- 关系检索:基于知识图谱获取实体与关系;
- 上下文融合:将非结构化与结构化信息联合构建提示,供 LLM 生成最终答案。
五、GraphRAG 的优势场景
GraphRAG 并不会完全替代 Vector RAG,但在某些场景中优势明显。
1. 复杂关系分析
例如:
Company A
└─ owns → Company B
└─ purchases → Supplier CGraphRAG 可以进行多跳关系查询。
2. 企业数据整合
企业数据通常分散在:
- CRM
- ERP
- Ticket系统
- 知识库
- API
知识图谱可将这些异构数据源统一关联。
3. 可解释 AI
Graph 查询结果是结构化的,因此 AI 回答具有可解释性,例如:
Tesla
└─ battery supplier → Panasonic用户可以清楚看到推理路径。
六、技术选型建议
不同场景适合不同架构:
| 场景 | 推荐架构 |
| 企业文档问答 | Vector RAG |
| 复杂关系数据 | GraphRAG |
| 企业知识平台 | Hybrid RAG |
七、总结
RAG 架构正经历从 Vector RAG 到 GraphRAG,再到 Hybrid RAG 的演进。Vector RAG 擅长语义搜索,GraphRAG 擅长关系推理,而混合架构则融合二者优势。随着企业 AI 应用的不断深入,未来的智能知识系统将更广泛地依赖向量数据库、知识图谱与大语言模型,三者共同构成下一代企业 AI 数据架构。












