.png)
摘要
聚焦企业原始文档向可检索向量知识库的转化问题,完整拆解从文件清洗、向量化、索引构建到混合检索的全链路技术逻辑,解决POC到生产环境的架构、效能、落地三大困境。

一、直播概述
本次直播为Redis企业级实战系列第二期,聚焦企业级知识库与向量索引实操全链路流程,核心解决企业原始文档向可检索向量知识库的转化问题,拆解从POC到生产环境的架构、效能、落地三大困境,完整梳理从文件清洗、向量化、索引、混合检索等全链路技术逻辑。
Redis凭借内存架构、多线程Query Engine,及RedisJSON与Hybrid Search的深度融合,实现低延迟、高吞吐、高可靠的向量检索,在技术栈复杂度、运维成本、企业业务适配性上优势显著,成为企业级RAG架构的核心基础设施,为解决大模型幻觉问题提供坚实支撑。
二、核心亮点回顾
1. 资料准备与Chunk策略
这是RAG品质的第一道防线,核心将混乱的企业文档转化为标准化知识库素材。先对Markdown、PDF等多格式文档做文本抽取、正规化处理,解析部门、语言等元数据形成结构化数据;因大模型上下文限制,需将文档切分为独立Chunk。
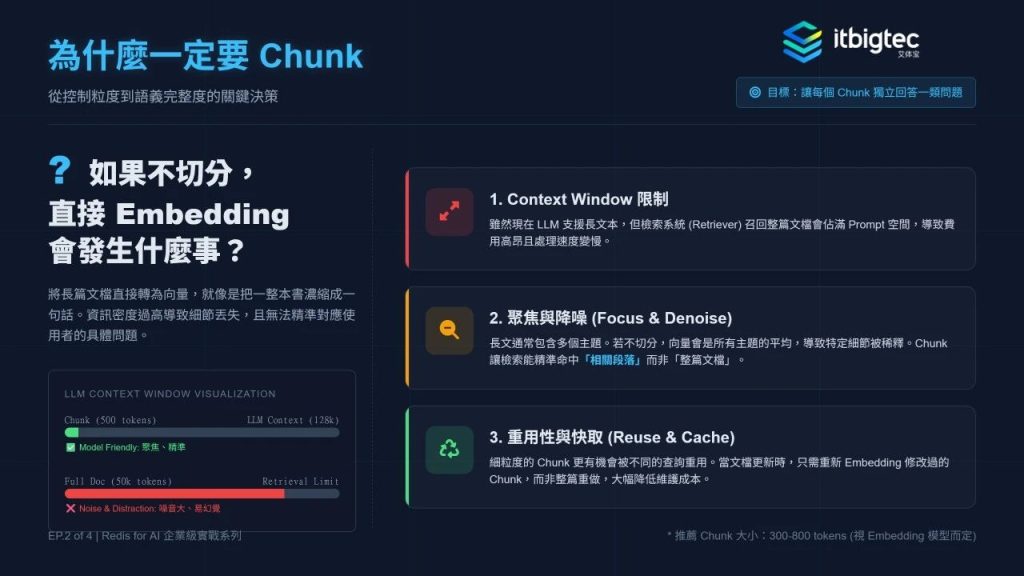
主流有固定长度+重叠、章节切分两种策略,分别适配无结构/结构化文本,过长章节可二次滑窗。RedisJSON可将Chunk的内容、元数据、向量储存在单Key中,为混合检索奠定基础。
2. Embedding与向量写入Redis
本阶段实现文本向量化与向量向Redis的生产级写入,平衡成本、质量与效能。推荐选用OpenAI text-embedding-3-small模型,兼顾成本与效果;采用批量处理模式,减少API往返次数,将向量与Chunk组装为RedisJSON结构后,通过Pipeline批量写入,提升吞吐量。
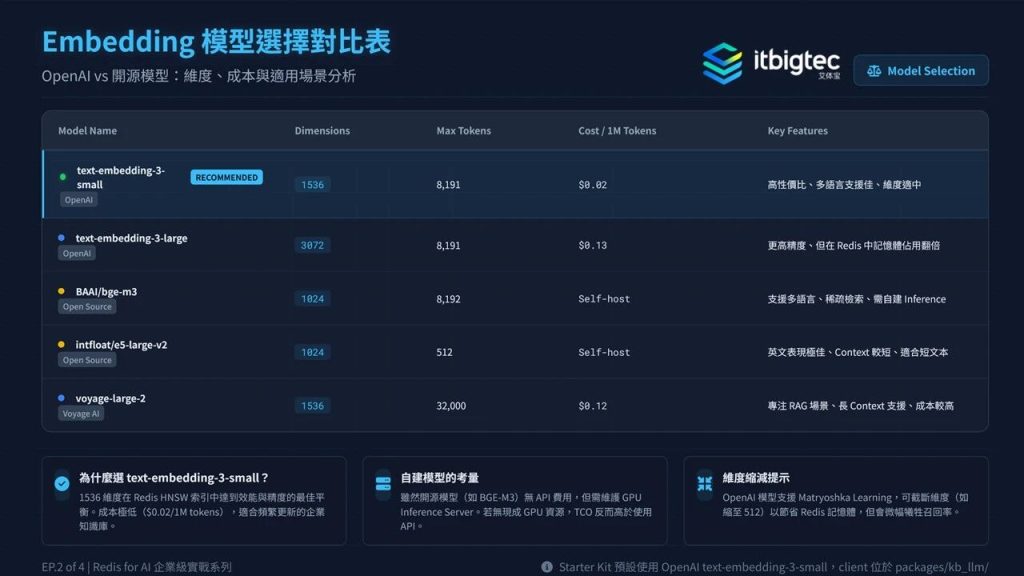
Redis依托内存架构等特性支撑高吞吐,同时支持Int8量化节省75%内存,搭配指数退避重试、死信队列等容错机制,及核心指标监控告警,保障生产级写入可靠性。

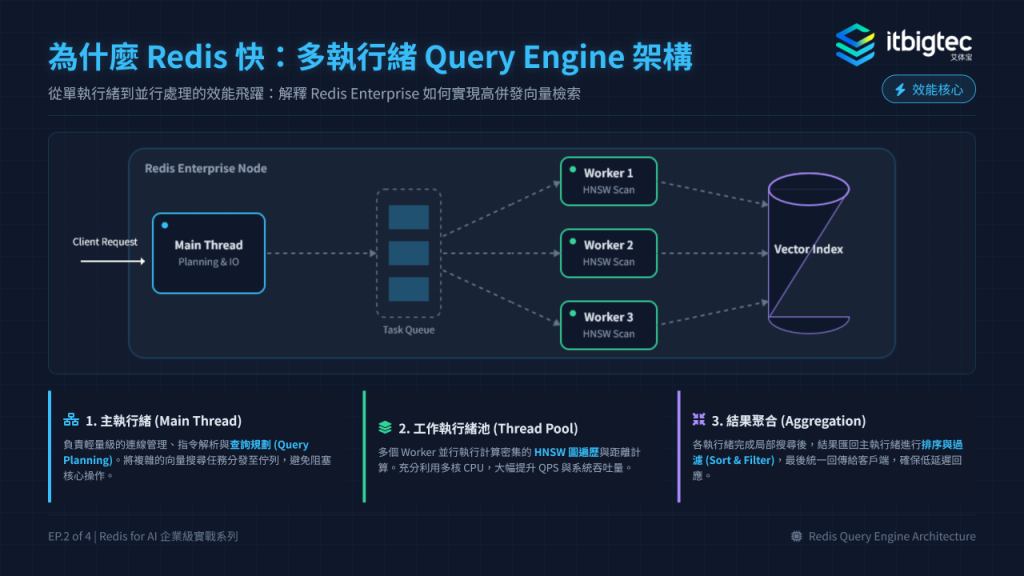
3. 建立Redis向量索引
本阶段核心解决全表扫描的效能瓶颈,实现毫秒级KNN检索。全表扫描延迟随数据量线性上升,无法满足企业级检索需求,需构建向量索引将检索复杂度从O(N)降至O(log N)。Redis提供FLAT和HNSW两种索引,FLAT适合POC/小规模数据,生产环境首选HNSW算法,通过M、EF_CONSTRUCTION等参数调优可平衡召回率与延迟。

基于Redis Stack构建JSON联合索引,多线程Query Engine并行处理检索任务,相比其他向量库,Redis在QPS和延迟上具备显著优势。
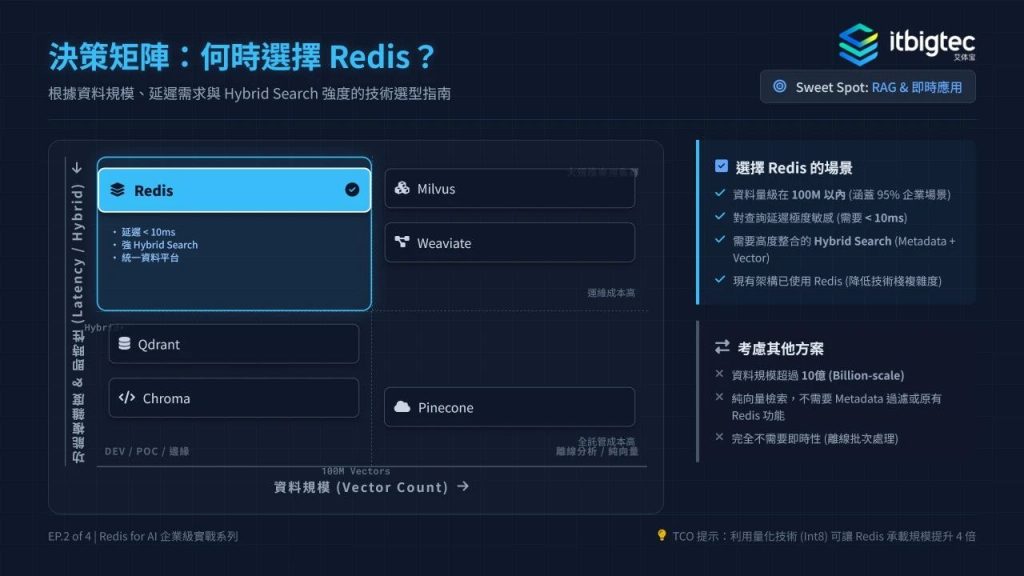
4. Hybrid Search与业务场景落地
本阶段是Redis企业级检索的核心价值所在,实现向量KNN检索与业务元数据过滤的深度融合。通过`FT.SEARCH`指令完成单阶段原生混合检索,先做元数据前置过滤,再执行向量检索,一次往返即可完成,延迟低于10ms,适配多租户权限、多语言检索、版本时效性控制等典型企业场景。

对比其他向量库,Redis混合检索无需多阶段处理,支持复杂JSON元数据,且无需新增基础设施,TCO更优。100M以内向量、低延迟需求的场景优先选Redis,超大规模纯向量检索可考虑其他方案。