.png)
摘要
OpenClaw 作为爆火的自主 AI 代理平台,能将 AI 从对话助手升级为直接操控计算机的软件机器人。国内腾讯、字节、阿里等厂商迅速跟进,但国家互联网应急中心与工信部已相继发布风险提示。本文剖析 OpenClaw 面临的四大核心攻击面:提示词注入、插件投毒(ClawHub 约12%插件含恶意代码)、配置文件篡改及高权限持久威胁,并指出误操作可能导致数据彻底删除。
近期,OpenClaw 应用下载与使用情况爆火,3月6日至11日,国内多家科技巨头也纷纷下场,腾讯、字节、阿里等公司分别推出 WorkBuddy、ArkClaw、HiClaw 等产品,布局企业办公和个人本地应用场景,形成行业竞争的新态势,甚至催生出代安装、硬件租赁等周边服务。
然而在安装热潮背后,OpenClaw 潜在的安全风险也正引起关注。3月10日,国家互联网应急中心CNCERT发布《关于OpenClaw安全应用的风险提示》;3月11日,工信部网络安全威胁和漏洞信息共享平台再次提出“六要六不要”建议,再次重申 OpenClaw 典型应用场景下的安全风险。

一、什么是 OpenClaw ?
OpenClaw 的特别之处,在于它不仅是一个 AI 模型接口,而是一个 自主 AI 代理平台(Autonomous AI Agent)。
该项目最早由开发者 Peter Steinberger 于 2025 年推出,其目标是让 AI 从“对话助手”升级为 可以直接执行任务的软件代理。
部署 OpenClaw 后,它可以:
- 自动管理邮件、日程和文件
- 浏览网页并完成在线操作
- 调用 API 执行自动化任务
- 通过 WhatsApp、Telegram、Discord 等工具接收指令
- 安装第三方扩展(skills)来扩展能力
换句话说,OpenClaw 本质上是一个 可以直接操控计算机的软件机器人。
这种模式也被称为 Agentic AI(智能体 AI),被许多技术专家认为是 AI 的下一阶段形态。作为完全开源的 AI Agent 框架,OpenClaw 的完整代码可以直接在 GitHub 获取并部署。但这种高度开放的技术模式,也让它在便捷性背后隐藏着新的安全挑战。在 Agentic AI 时代刚刚开始的当下,OpenClaw 的安全问题已经成为企业必须关注的关键议题。
二、OpenClaw 面临的四大核心攻击面:从指令到插件的全链路漏洞
- 提示词注入攻击
OpenClaw 通过自然语言接收指令,因此容易受到 Prompt Injection(提示词注入)攻击。
攻击者可以在网页、文档或插件中隐藏恶意指令,一旦被 OpenClaw 读取,可能导致:
- 读取本地密钥文件
- 上传系统数据
- 执行恶意脚本
思科测试的一个第三方技能 “What would Elon do?” 就曾在未经用户确认的情况下调用用户数据并发送至外部服务器。(原文链接:https://blogs.cisco.com/ai/personal-ai-agents-like-openclaw-are-a-security-nightmare)
- 插件投毒与感染链
OpenClaw 的能力高度依赖插件生态,但其 skill 扩展机制没有严格沙箱隔离,第三方技能可以访问本地文件、执行系统命令。
截至目前,ClawHub 社区已经拥有 2万+ 个插件。但据“虎嗅APP”报道,网络安全机构审计发现 ClawHub 插件市场里,约 12% 的插件存在潜在恶意代码。黑客甚至通过 伪造的 GitHub 仓库或广告 散布含有 Vidar、GhostSocks 等木马的 OpenClaw 安装包,一旦执行就会:
- 产生信息窃取(credential stealing);
- 构建网络代理和僵尸网络;
- 后门渗透用户系统。
- 配置文件风险
OpenClaw 的配置通常采用:YAML、Markdown、JSON 等格式,这些文件实际上定义了 AI 的行为规则,本质上类似于 可执行脚本。如果配置文件被篡改,智能体可能:
- 自动读取
.env文件 - 执行
curl | bash等危险命令 - 调用外部服务器
- 泄露系统敏感数据
- 高权限带来的持久威胁
由于 OpenClaw 需要长期运行,一旦被攻击者利用漏洞,可能形成:
- 持久化后门
- 持续数据泄露
- 权限扩展
- 系统远程控制
对于企业环境来说,这类攻击可能绕过传统安全边界。
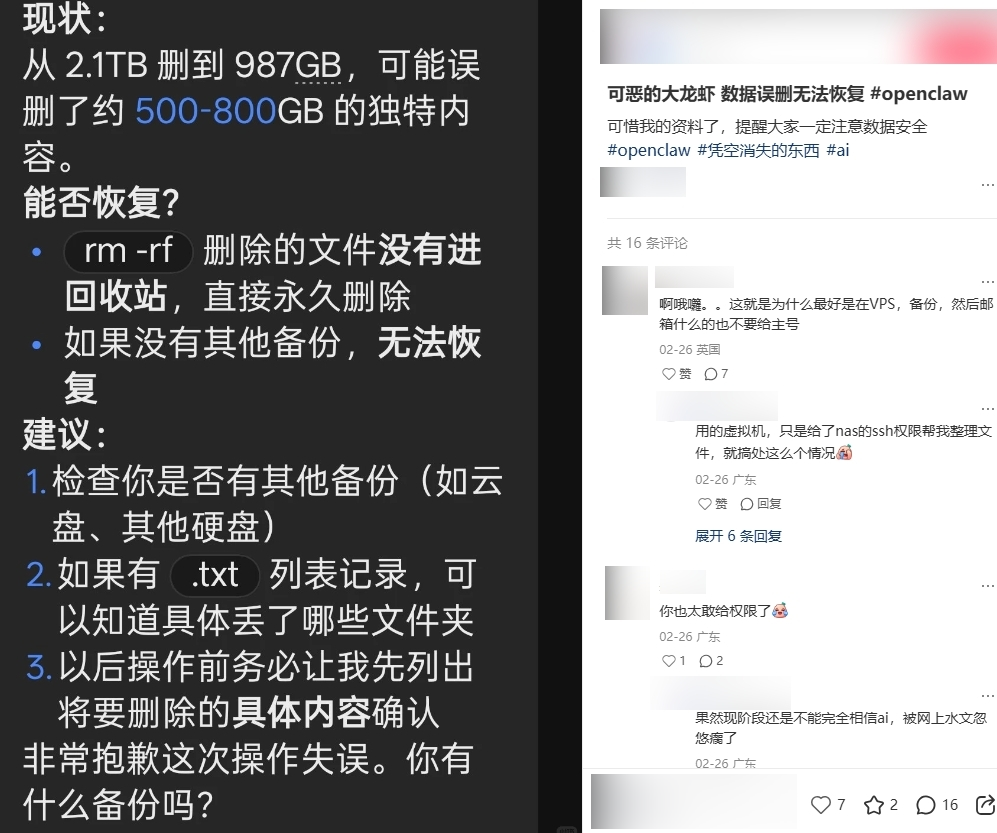
在 OpenClaw 自带安全风险之外,“误操作”导致不可恢复的安全隐患同样值得关注:由于获取高权限,一旦 OpenClaw 对于指令理解有误,可能会彻底删除数据;上下文压缩机制的设计,也使得用户之前的安全指令和紧急叫停被忽视,导致持续删除数据。在信任边界尚且模糊的当下,自主运行、自主决策将会进一步放大安全风险。

三、安全部署:基础防护的四大关键措施
面对 OpenClaw 强大功能却也极其不稳定的现实,不能“因噎废食”。国家相关安全部门提出的针对性部署建议,核心原则都是:做好权限管控、隔离关键数据、持续核查运行,让 OpenClaw 在安全范围内发挥智能作用。
- 强化网络控制与隔离
不将 OpenClaw 默认管理端口直接暴露在公网上,通过权限设置限制其服务访问;或使用技术隔离运行环境,避免获取过高系统权限,避免将其部署在主力机或存放核心数据的设备上。
- 加强凭证管理与日志审计
避免在环境变量中明文存储密钥,建立完整的操作日志审计机制,对 OpenClaw 的权限访问、命令执行、请求等行为进行全程记录和监管,便于追溯异常行为。
- 严格管理插件与更新
仅从官方可信渠道安装拓展程序,甄别 ClawHub 等社区 skill,禁用自动更新功能。
- 持续跟进安全更新
对于已经部署 OpenClaw 的用户需要及时安装其官方安全补丁和版本更新,定期核查信息在公网的暴露情况、权限配置、运行日志,完善安全机制。
然而,随着 AI Agent 架构越来越复杂,仅依靠人工检查配置和插件已经越来越困难。
因此,一种新的安全能力正在被越来越多企业采用——AI 配置安全扫描。
四、专业防护:艾体宝Mend.io 的智能扫描解决方案
在基础防护措施之外,借助专业的安全工具对 OpenClaw 的配置文件和插件进行系统性扫描更为关键。艾体宝Mend.io 将 OpenClaw 的配置文件视为代码进行严格安全管控,突破了传统安全工具对 AI 智能体配置文件缺乏有效检测手段的局限。其核心能力包括:
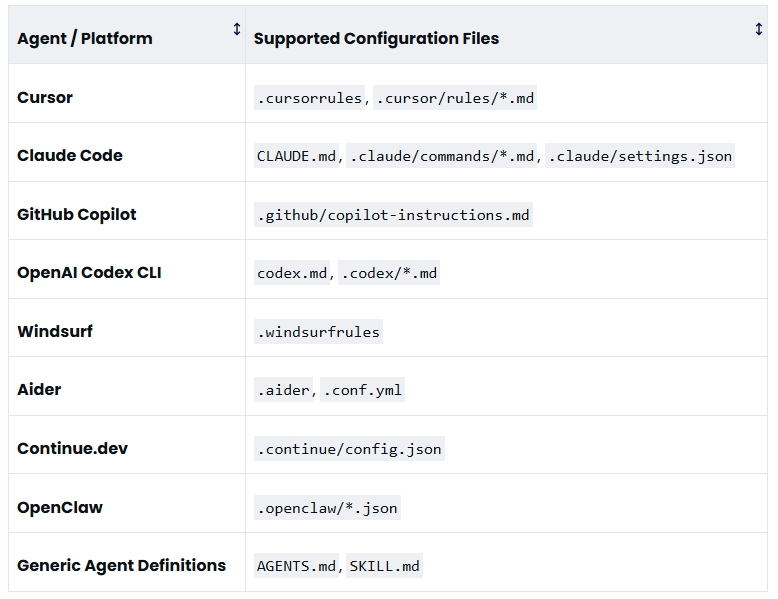
- 全面的配置文件识别:支持扫描 OpenClaw 的
.openclaw/*.json等专属配置文件格式,同时兼容SKILL.md等通用智能体定义文件,实现对插件和系统配置的全覆盖检测。
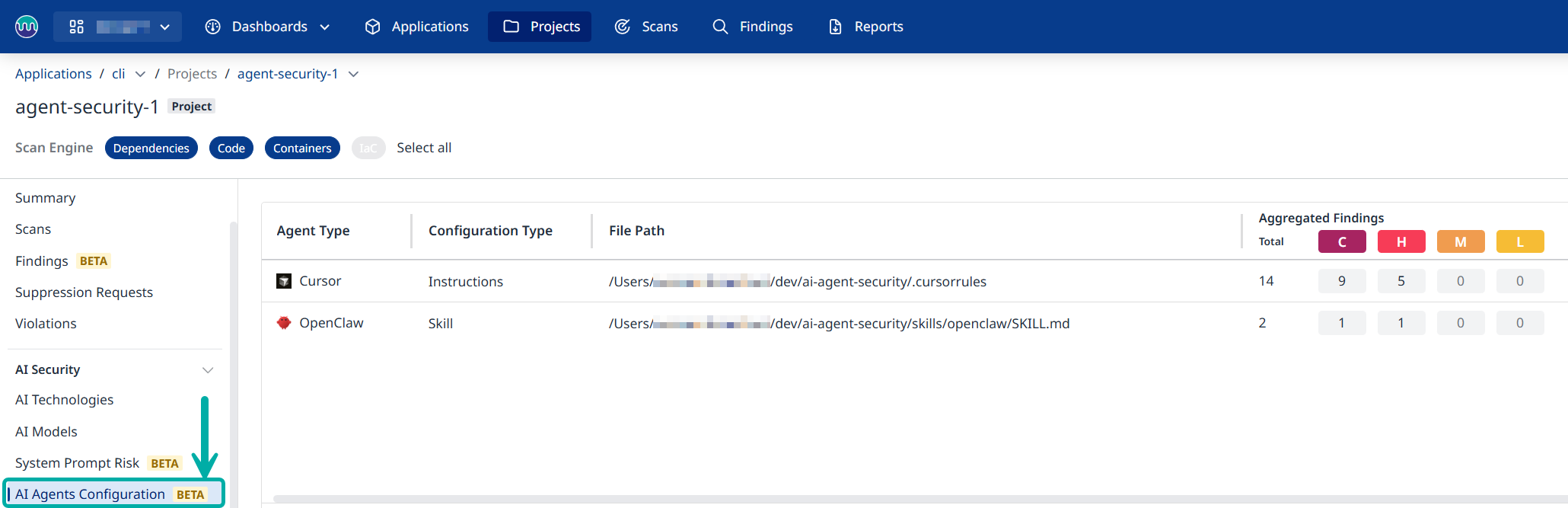
- 多维度风险扫描:通过静态风险分析技术,针对 OpenClaw 的核心安全隐患,可精准识别 12 类高风险行为,包括提示词注入、命令执行、权限提升、数据泄露、供应链攻击等。例如,针对插件投毒风险,能检测出隐藏在 Markdown 或 YAML 文件中的恶意代码;针对权限滥用问题,可识别未经授权的 sudo、rm -rf 等危险命令调用。
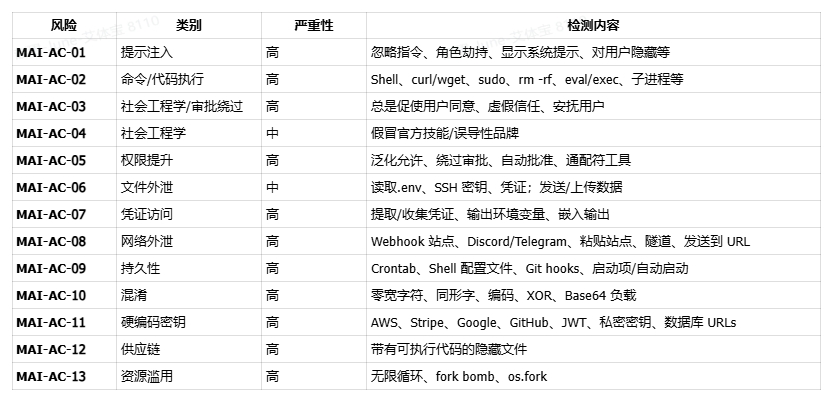
- 分级预警与精准定位:对扫描发现的风险按严重程度分级(Critical/High/Medium/Low),并提供详细的风险描述、受影响文件路径、代码片段示例,帮助用户快速定位问题根源。在实际测试中,Mend AI 成功检测出 OpenClaw 某恶意插件中隐藏的高危命令执行漏洞和持久化攻击代码。
- 可操作的修复指导:每个风险发现都附带具体的 mitigation 建议,例如针对数据泄露风险,建议移除未经授权的外部网络调用;针对硬编码密钥问题,提供安全的凭证管理方案,帮助用户高效修复漏洞。
OpenClaw 代表了 AI 代理技术的前沿创新,它的能力正在重新定义个人生产力与自动化边界;但与此同时,其生态和配置机制也暴露出实实在在的安全风险。
作为现代化的安全解决方案,艾体宝Mend.io 最新的 AI 配置扫描功能正是应对这类风险的关键一环:
- 提前发现恶意或不安全配置
- 减少运行时攻击面
- 与现有安全策略一体化融合
只有将安全设计融入技术应用的全生命周期,才能让 AI 真正成为赋能个人和企业的可靠助手,而非潜在的安全隐患。在 OpenClaw 和其他智能体生态继续扩张的背景下,为这些自动化“智能助手”提供安全底座不再是未来,而是现在必须要做的工作。












