.png)
摘要
在人工智能时代,企业在应用大语言模型时,普遍受困于三大痛点:幻觉问题、知识孤岛,以及延迟与成本问题。这些难题严重拖慢了数字化规模落地的步伐。RAG(检索增强生成)方案应运而生,其核心目标是借助真实数据,提升大语言模型生成内容的合规性和准确性。

一、直播概述
AI时代,企业使用大语言模型常常面临幻觉问题、知识孤岛、延迟与成本问题等三大痛点,阻碍规模化数字化转型落地的进程。RAG(检索增强生成)解决方案旨在用真实数据增强 LLM 内容生成的合规性与精准性。艾体宝×Redis 首期直播内容,便从向量资料库的核心概念入手,逐步拆解 Redis 如何凭借内存级速度、一体化架构及原生企业级特性,成为构建高性能、高性价比 RAG 系统的关键组件。
二、核心亮点回顾
1. 向量与语义搜索的本质
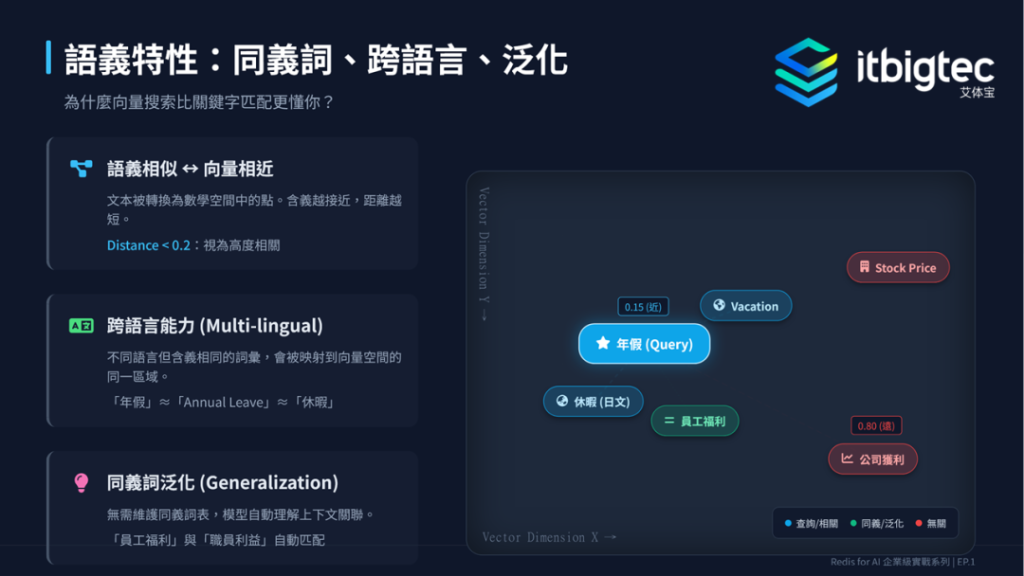
向量是语义的数学表达式,一段文字通过 Embedding 模型(如 OpenAI 的text-embedding-3-small)生成高维向量(如1536维),浮点数坐标代表语义位置。其核心有三大特性:语义相近则向量相近、具备跨语言能力、可实现同义词泛化,能精准捕捉文本语义关联。
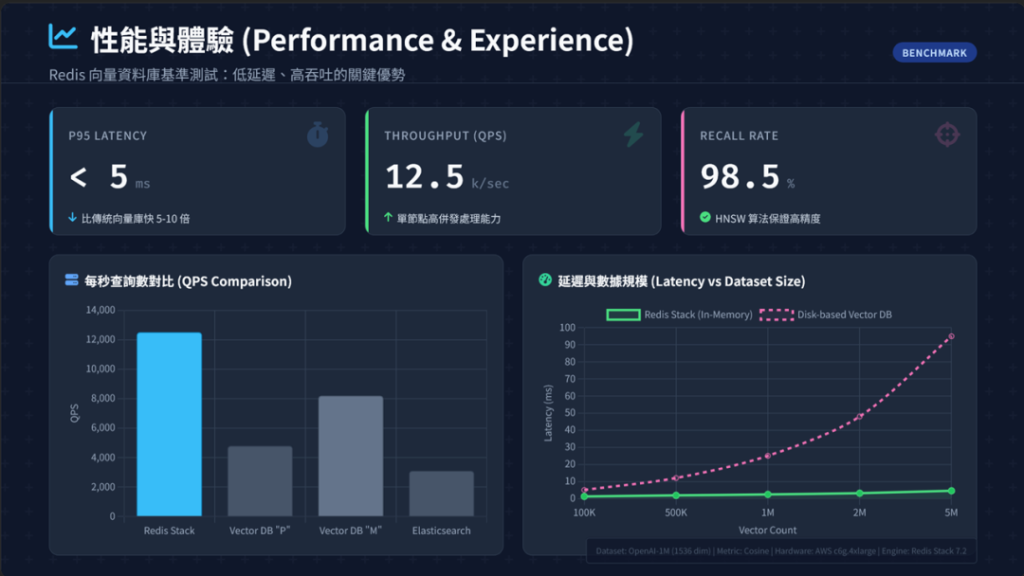
向量搜索分为三个核心步骤,首先是嵌入,将文本转化为向量,推荐优先使用 text-embedding-3-small,高精度需求可升级模型;其次是索引,RAG 级别首选 HNSW 算法,百万向量规模下查询延迟约5毫秒,召回率达95%。
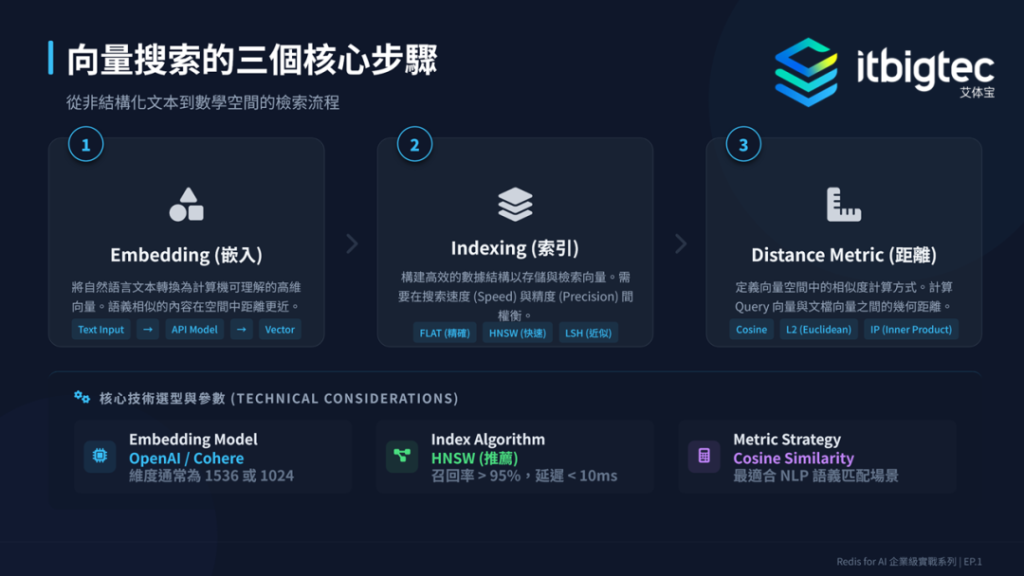
距离量度方面,文本语义搜索首选余弦相似度,欧式距离适用于图像或纯数值向量,内积多用于推荐系统。Redis 向量索引可通过 FT.CREATE 命令创建,合理设计命名空间,确保不同业务数据互不干扰。


2. RAG架构完整流程
- RAG 三阶段 :
RAG 架构分为检索、增强、生成三个核心阶段。检索阶段将用户查询向量化后进行 KNN 搜索,获取最相关文档片段;增强阶段整理片段为结构化上下文并附上元数据;生成阶段将上下文与问题输入大模型,注明引用以消除幻觉。
- 离线知识库构建流程 :
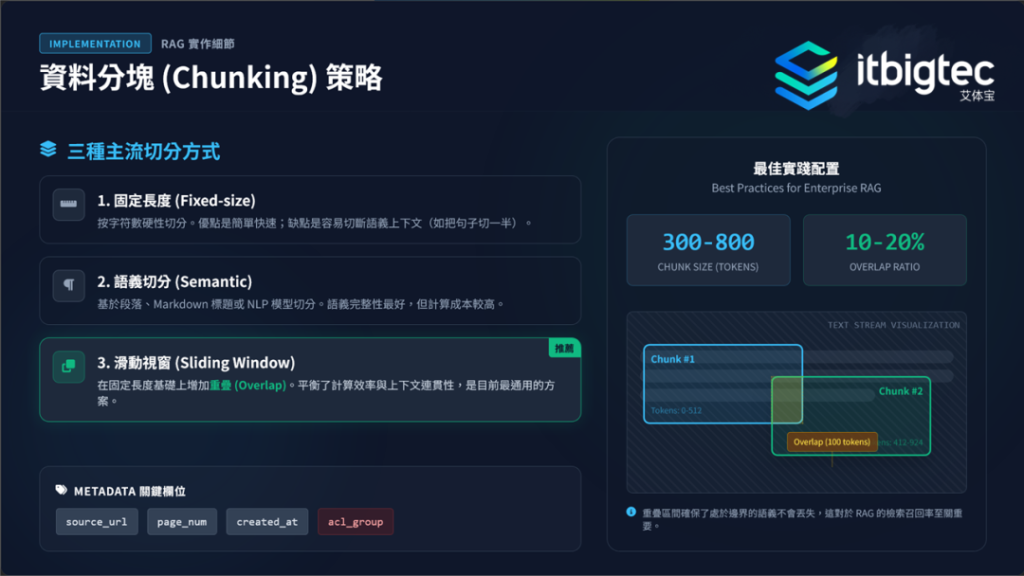
文档载入与智能分块 :载入 Markdown、PDF 等文件后进行分块,分块是影响 RAG 效果的核心步骤,主流方法包括:
离线知识库构建需先载入文档并智能分块,这是影响RAG 效果的核心。主流分块方法有三种,固定长度实现简单但易断语义,语义切分保证完整但成本高,滑动视窗是推荐方案,可平衡效率与连贯性。
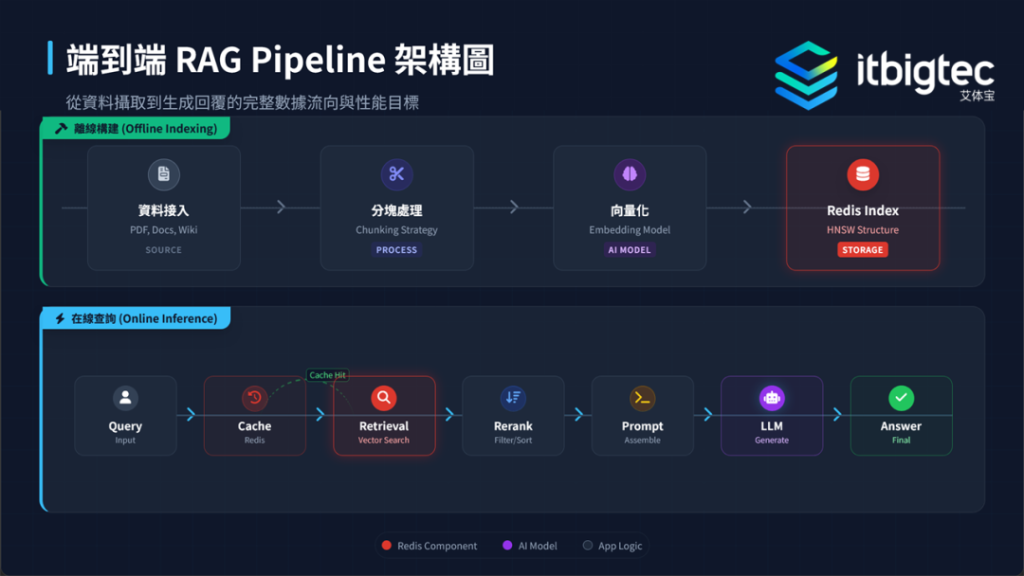
每个文档片段需包含 source URL、page number 等关键元数据,其中 ACL group 是企业级系统安全基础,能有效控制机密文档访问权限,保障数据安全,满足企业级应用的安全需求。
- 在线查询处理流程 :
用户提问后,先经过语义缓存(Semantic Cache),命中则直接返回结果;未命中则进行混合检索(Hybrid Search),获取相关文档,组装 Prompt 并调用大模型生成答案,同时更新缓存,整个流程为毫秒级响应。

- 常见失败模式与解决方案 :
RAG 应用中存在多种失败模式,均有对应解决方案。检索漂移可通过 Redis Stack 混合检索解决,Chunk 颗粒度不当可借助滑动视窗分块及元数据追溯,来源过期可加入时间加权因子保障时效性。

针对提示词污染问题,需实施内容过滤与边界防护,注入 Prompt 前过滤 PII 及恶意指令,同时明确 Prompt 分隔符与指令,避免大模型被误导,确保生成答案的准确性和安全性。
3.Redis 数据库的独特优势
Redis 的核心优势之一是速度,数据存储在内存中,查询延迟低于5毫秒,远超 SSD 向量数据库和传统数据库,适合对话式 AI、实时推荐等对速度要求极高的场景,Redis Enterprise 可平衡性能与成本。
Redis 具备强大的一体化能力,传统架构需组合多种系统,而 Redis 可在同一集群中处理向量搜索、缓存、业务数据等多种任务,大幅简化架构,降低延迟和运维成本,提升运营效率。
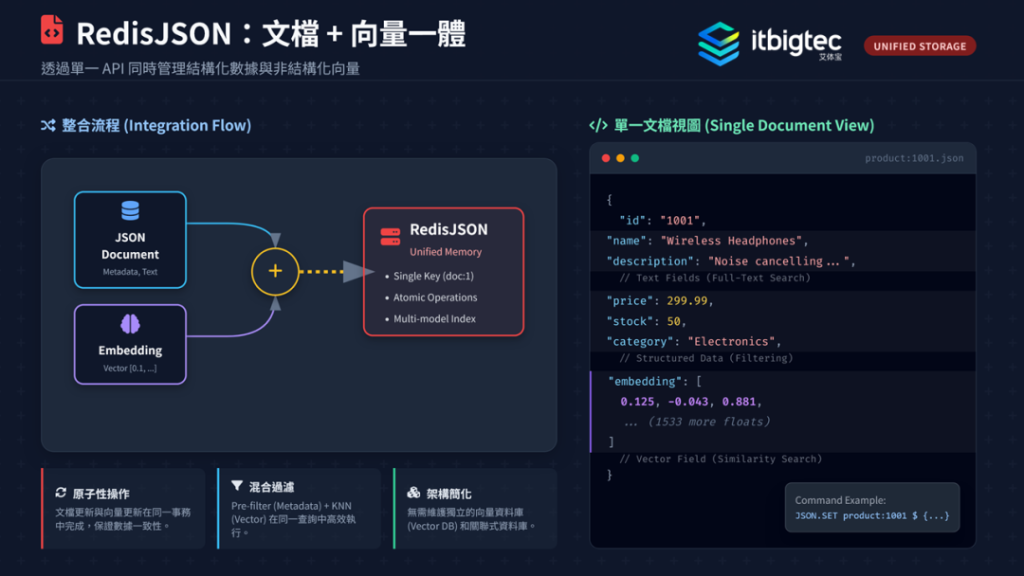
Redis Stack 原生支持混合检索和 Redis JSON,可实现文档与向量一体化存储与查询,无需复杂集成,大幅降低开发与部署难度,为 RAG 系统构建提供便捷支撑。
语义缓存的高性价比是 Redis 的另一核心优势,通过Redis 实现的语义缓存平均命中率达42%,高频场景更高,可减少35%的 Token 消耗,降低延迟,是企业规模化应用 RAG 的成本关键。
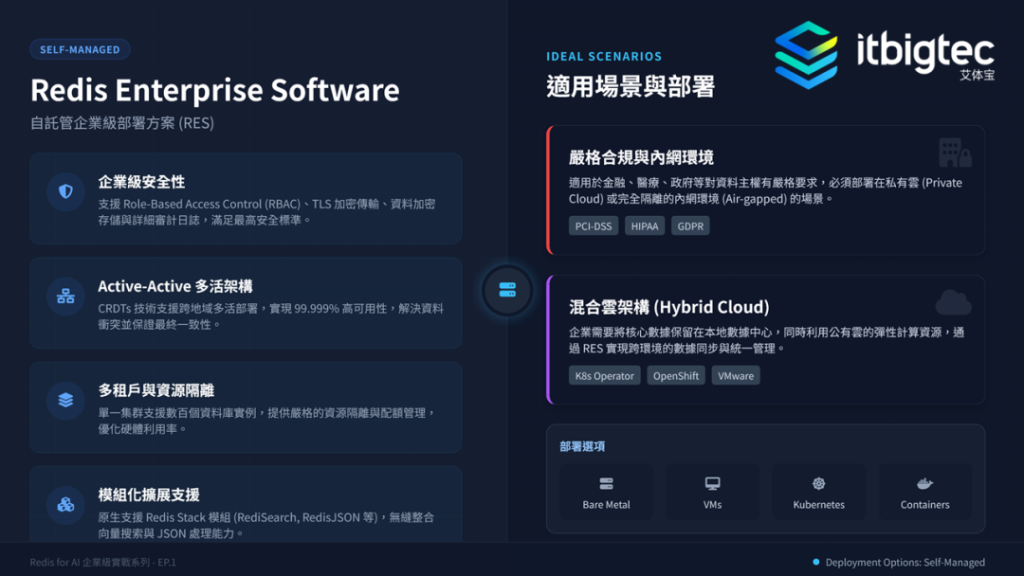
Redis 企业版具备完善的企业级特性,提供分片主从复制、30秒自动故障转移的高可用能力,支持 RDB+AOF 数据持久化,还有RBAC安全控制等特性,满足生产环境严苛要求。